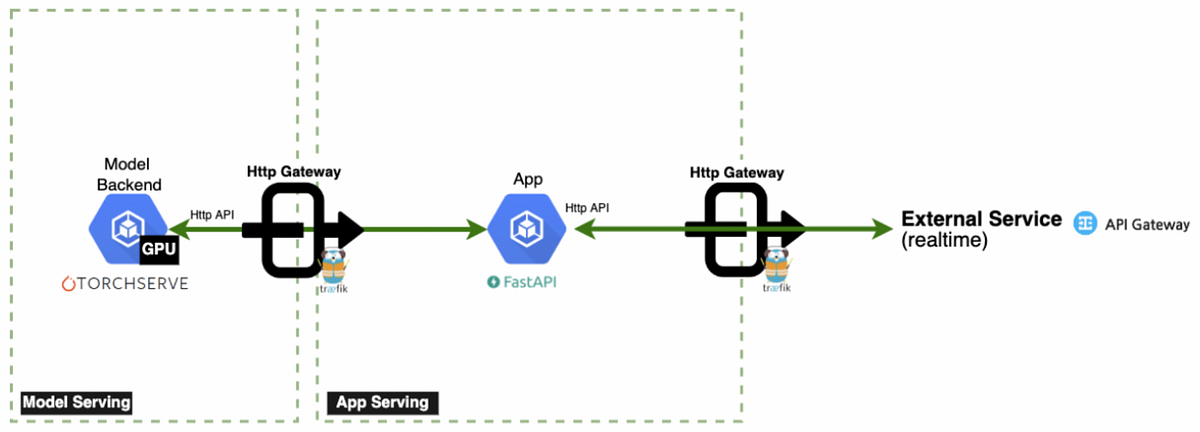
핵심 요약
현대자동차가 PyTorch 2.x Torch Compile로 추론 속도와 메모리 활용 최적화를 실험했습니다. 오픈소스 모델 mamba를 대상으로 평균 추론 시간이 약 32.8% 감소했고, P90/P99도 각각 약 29.9%와 33.0% 개선했습니다. 학습 시간은 소폭 증가했고 메모리는 상황에 따라 변동이 있었습니다.
주요 경험
- 1줄 코드로 torch.compile(model) 적용이 가능합니다.
- TorchDynamo/AOTAutograd/PrimTorch/TorchInductor가 자동 최적화를 수행합니다.
얻은 인사이트
- 실행 경로 최적화를 위해서는 먼저 컴파일 적용이 필요하며, 저장 시 _orig_mod 접두사 문제를 주의해야 합니다.
- ONNX 내보내기는 dynamo_export 사용을 권장합니다.