핵심 요약
Naver Place가 GPU 모델 서버의 성능을 유지하면서 CPU 서버로 전환해 연간 비용 약 4억원 절감 및 한국·일본에서 GPU 15대 절감 효과를 달성했습니다.
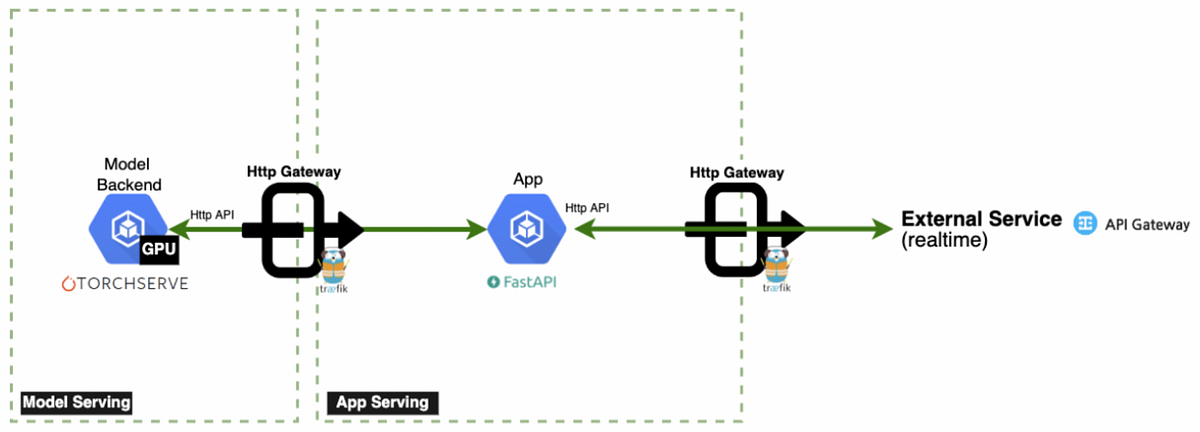
구현 방법
- TorchServe 기반 CPU 인퍼런스 아키텍처로 전환하고 App Server(FastAPI)에서 전처리/후처리 수행
- Traefik gateway mirroring으로 staging/production 간 트래픽 안전 검증
- CPU 성능 최적화: 물리 코어에 맞춘 thread 수 조정 및 Intel ipex를 통한 socket pinning으로 GEMM 병목 제거
- 모델 경량화: Knowledge Distillation 도입 및 입력 해상도 축소 병행
주요 결과
- GPU 15대 절감으로 연간 약 4억원 비용 절감
- RPS 약 3배 이상 개선, ipex 도입으로 추가 개선
- 특정 KD 적용 모델에서 2.5rps→84rps로 대폭 개선

