핵심 요약
버즈빌은 Honeyscreen의 콘텐츠를 카테고리 기반으로 효율적으로 클러스터링하기 위해 word2vec를 활용하는 방법을 소개합니다.
구현 방법
- 콘텐츠의 의미 기반 클러스터링과 협업 필터링의 두 가지 접근을 설명
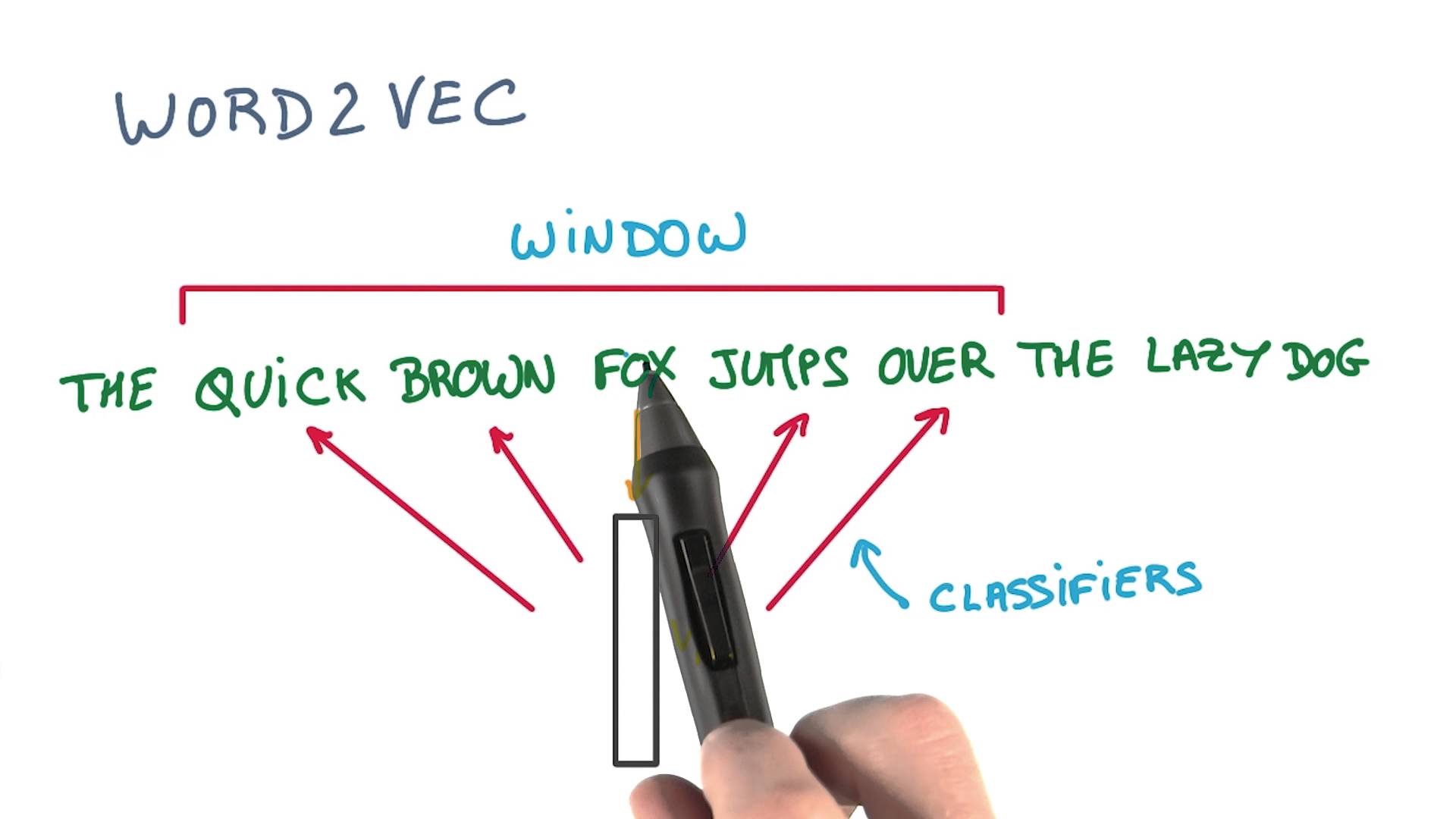
- word2vec를 이용해 단어 벡터를 학습하고 벡터 간 유사도로 콘텐츠를 클러스터링
- LDA, TF-IDF 등 NLP 기법도 함께 활용하며, 일반 노트북에서도 학습이 가능하도록 최적화
주요 결과
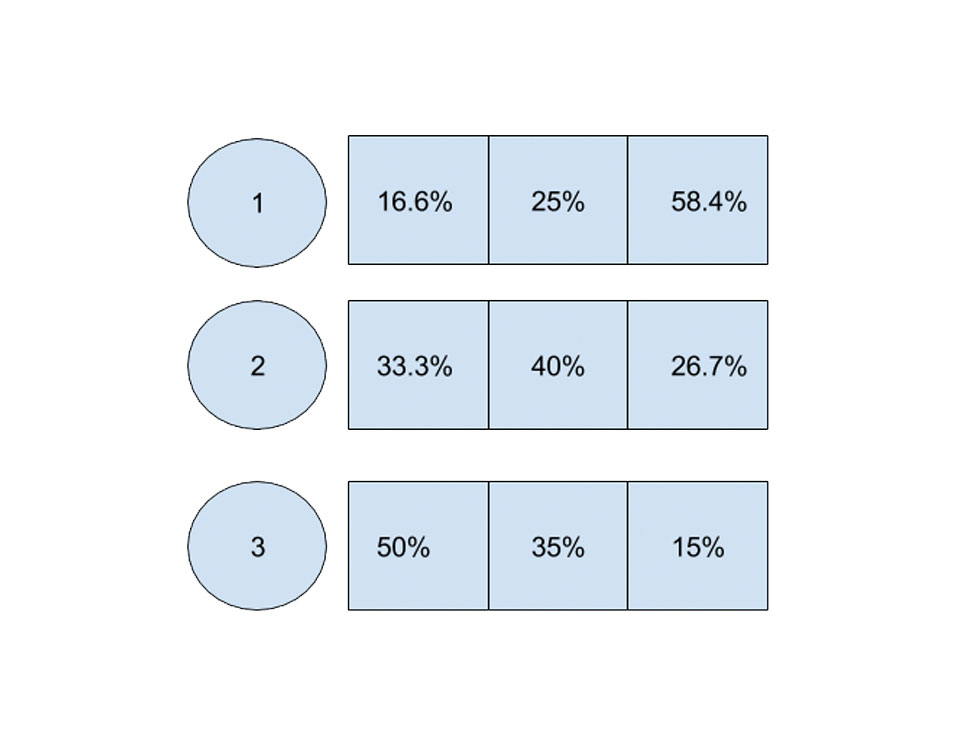
- 본문에 구체적 성과 지표는 제시되지 않음
- word2vec의 개념적 이점과 적용 가능성에 대해 논의