핵심 요약
당근 데이터 가치화팀은 컬럼 레벨 리니지 파싱과 자동화 파이프라인 구축으로 데이터 흐름의 가시성과 신뢰성을 높인 사례를 공유합니다.
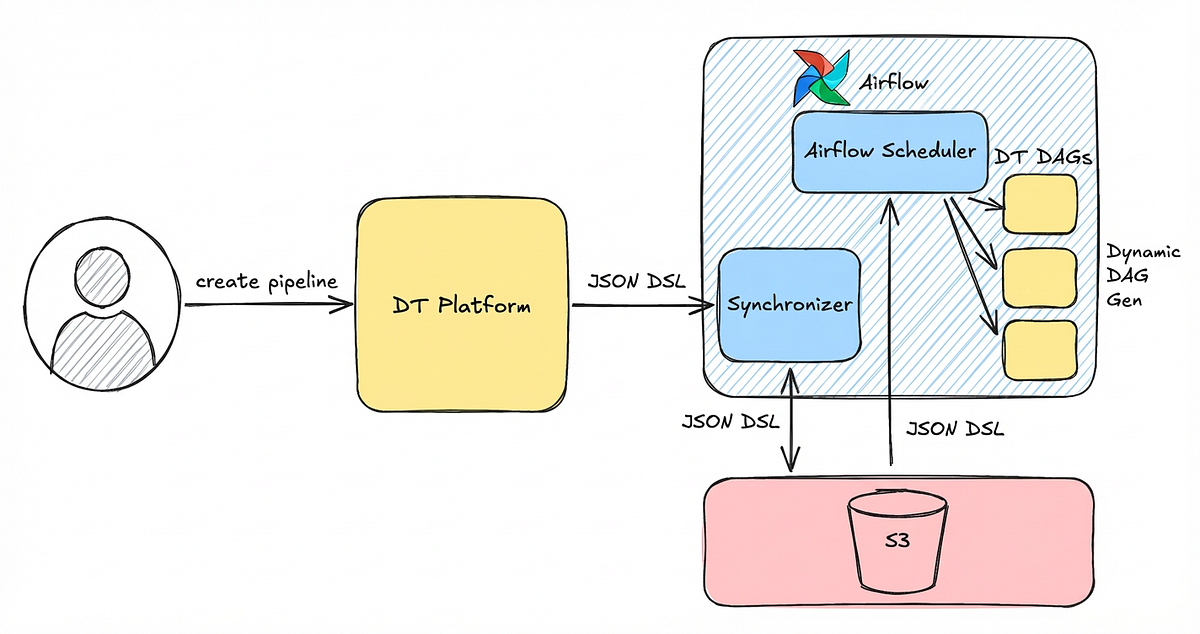
구현 방법
- BigQuery INFORMATION_SCHEMA.JOBS에서 실행 쿼리 로그를 수집하고 sqlglot로 파싱하여 컬럼 간 의존성을 추출합니다.
- 추출 결과를 Spark로 병렬 처리해 데이터_catalog.lineage에 저장하고, CTE/서브쿼리 처리도 단계적으로 해석합니다.
- 운영·확장: Airflow로 스케줄링하고 MCP Server로 빠른 조회를 제공하며, 원본(raw) 테이블 위에 목적별 View를 구성합니다.
주요 결과
- 매일 전날 쿼리 로그를 분석해 리니지를 자동으로 업데이트합니다.
- 하루 약 15,000개의 테이블과 80만 개의 컬럼 의존 관계를 추적합니다.
- MCP Server를 통해 몇 초 이내에 리니지 정보를 조회할 수 있습니다.