핵심 요약
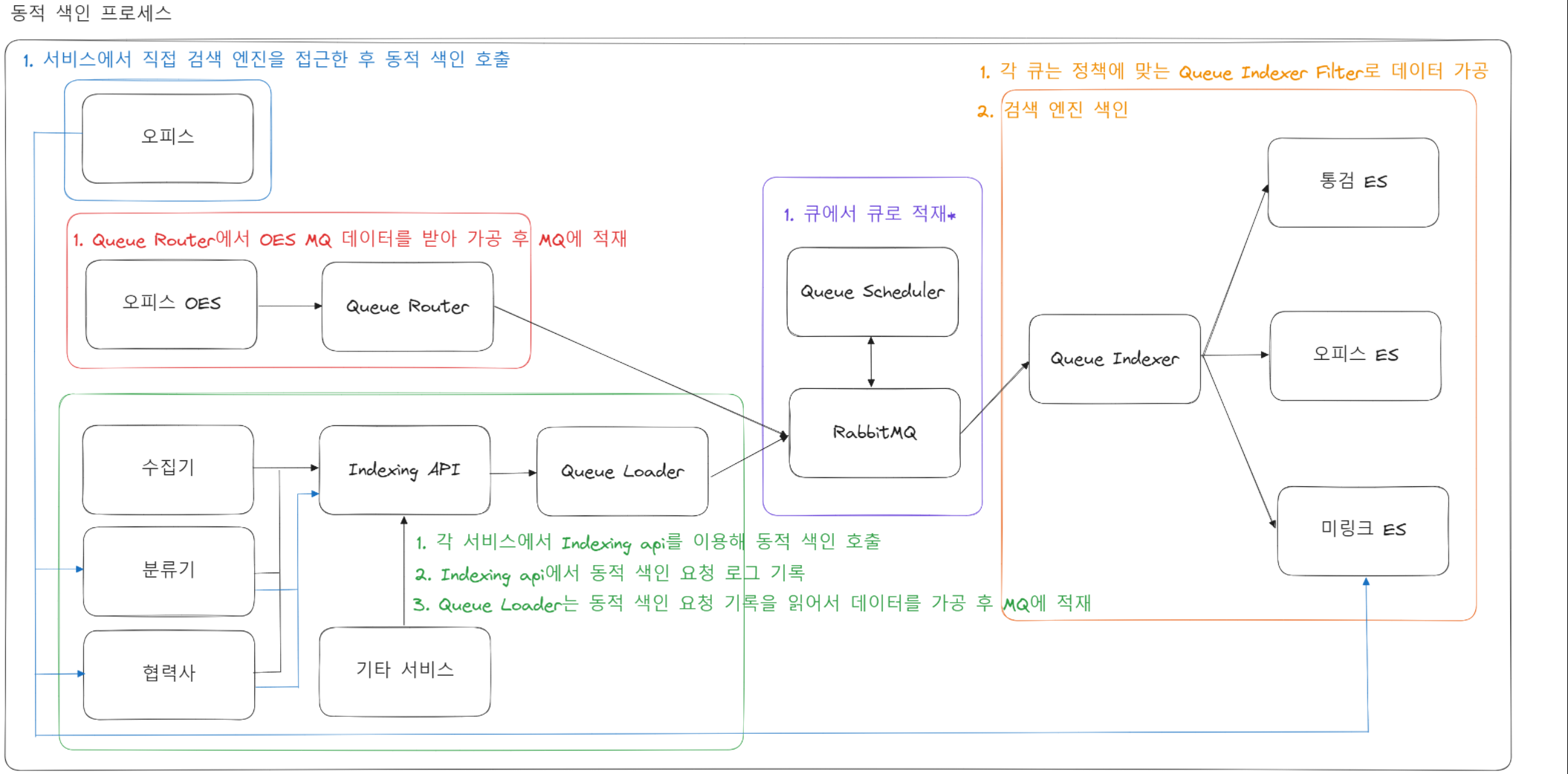
다나와의 상품 데이터 여정을 통해 수집기-분류기-오피스-검색으로 대용량 데이터를 자동·수동으로 분류하고 색인하는 전체 데이터 흐름을 설명합니다.
구현 방법
- 수집기: 협력사 데이터의 대용량 수집(MB~GB 규모; GB일 때 억 단위의 데이터)을 분류기로 전달합니다.
- 분류기: 카테고리 대분류→소분류 구조에 맞춰 자동 분류하고, 유사 상품 묶음 및 동일 상품 병합으로 데이터 품질을 향상하며, 최저가를 갱신합니다.
- 오피스: 수동으로 분류되지 않은 상품을 보완하고, 상품 링크 부여와 데이터 수정을 수행하며, 변경 알림을 타 서비스에 전달합니다.
- 검색: 미링크 상품의 형태소 분석과 상품명 분석으로 색인 최적화를 진행합니다.
주요 결과
- 대용량 데이터 관리가 가능해졌고 자동 분류와 수동 보완으로 데이터 품질이 향상되었습니다.
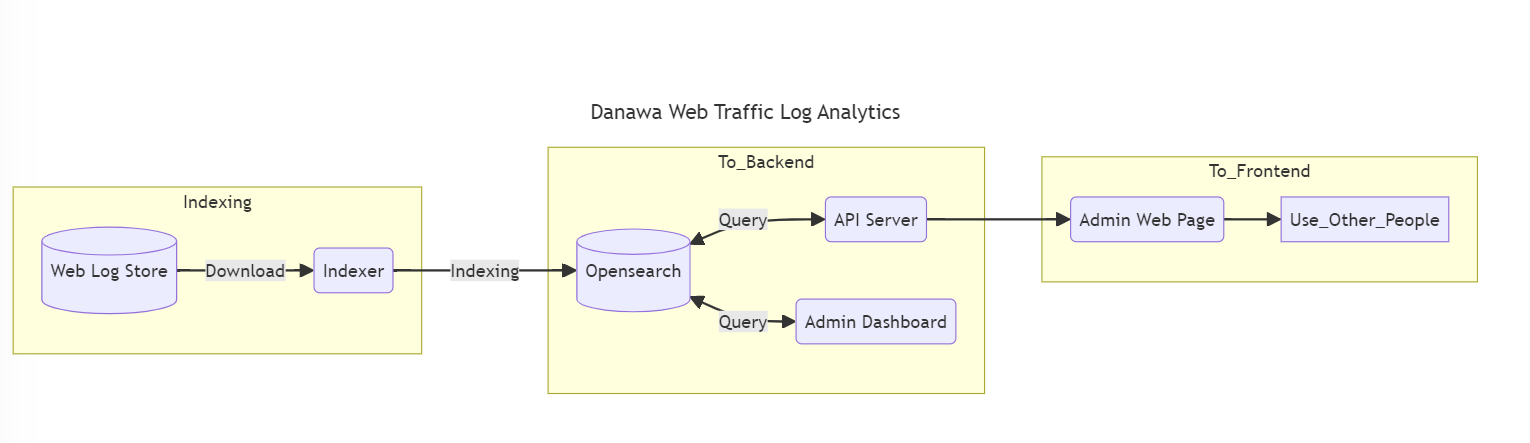
- 데이터가 다나와 페이지 및 관련 서비스에 안정적으로 반영되어 사용자에게 정확한 정보를 제공합니다.