핵심 요약
넷플릭스가 Casspactor의 한계를 극복하기 위해 백업에서 직접 Spark DataFrame을 생성하는 엔진과 데이터 모델별 커넥터 팩토리를 도입해 Cassandra 데이터를 Iceberg으로 안정적으로 이동하도록 개선했습니다.
구현 방법
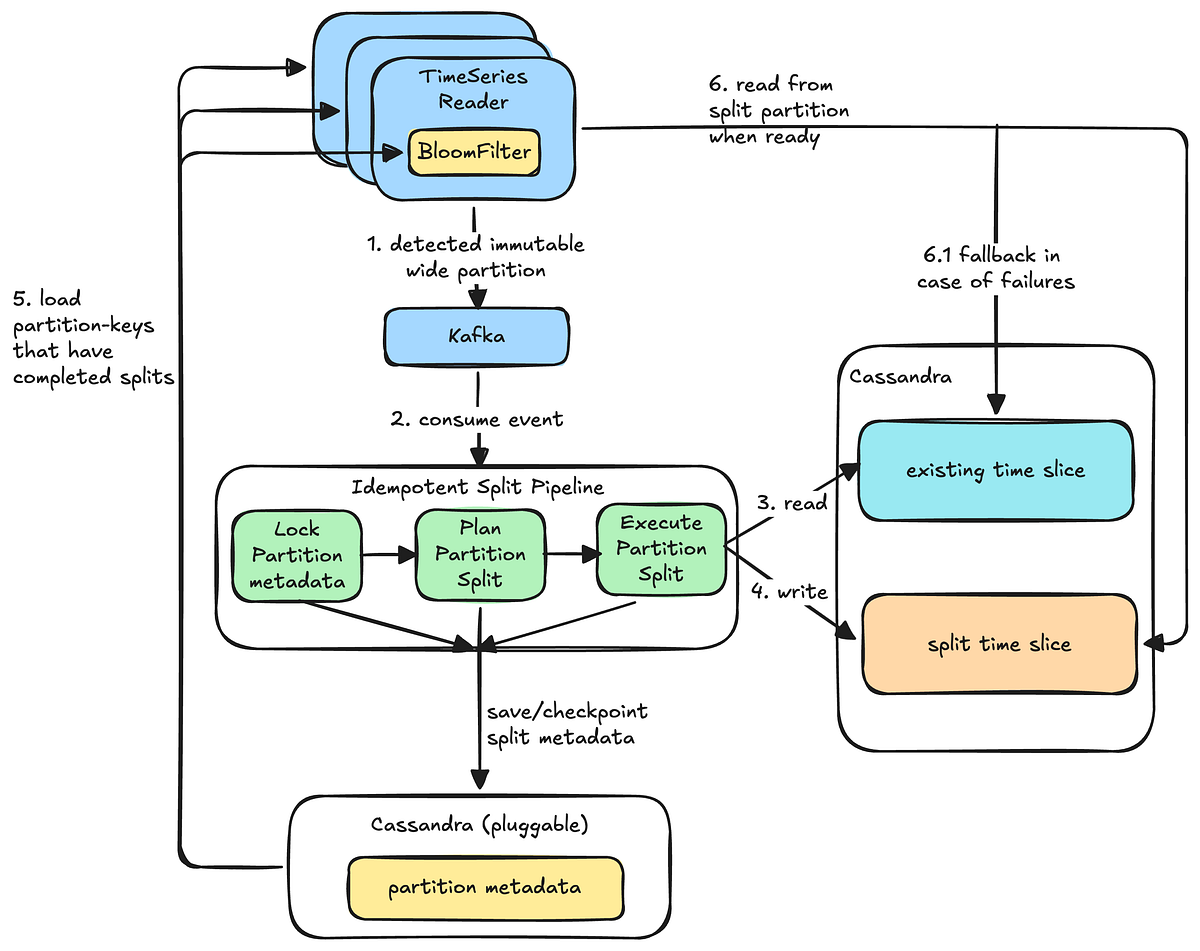
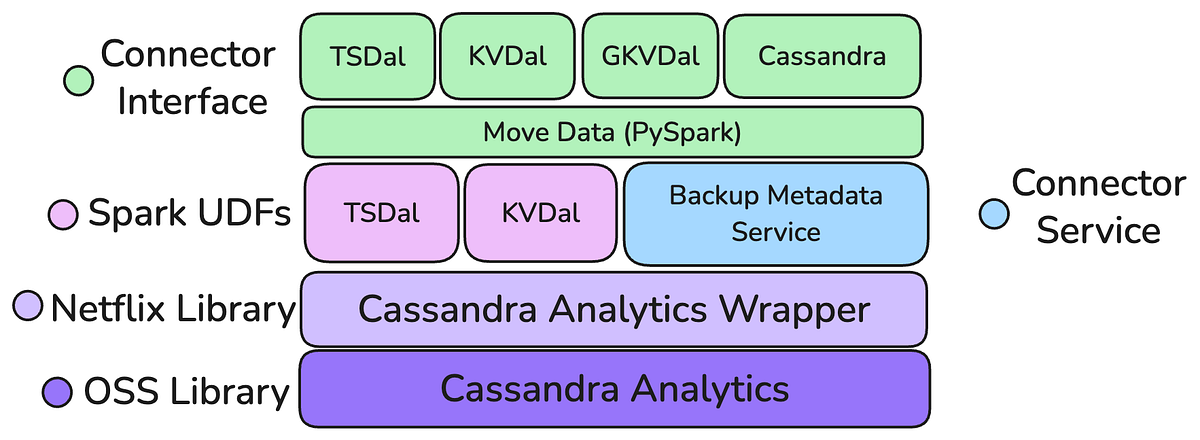
- Cassandra Analytics Wrapper와 S3 Client 기반 읽기 엔진으로 백업에서 데이터 추출
- 커넥터 팩토리(Java UDF/Transform)로 Key Value, Time Series 등 모델에 맞춘 변환 구현
- 중간 Iceberg 테이블 제거하고 백업(S3)에서 직접 Spark DataFrame 생성
- 실행기(Executor)에서 mutation 처리로 파티션 편향성 해결
- S3를 단일 진실 소스로 삼고 Time Travel 및 자동 사이징 도입
주요 결과
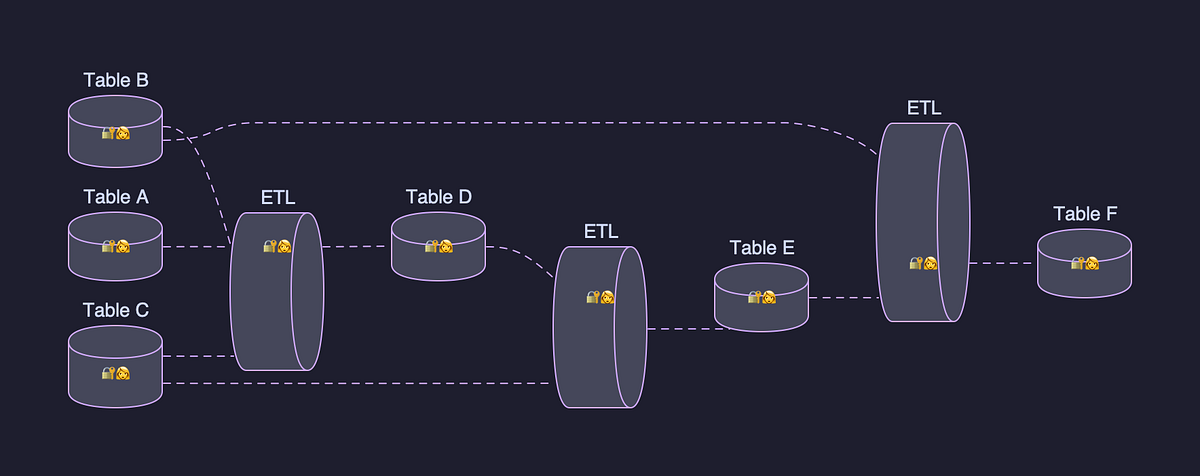
- Casspactor: 1,200건/일, 약 3PB 이동 규모에서 새로운 엔진의 성능/비용 이점 기대
- 런타임 감소 및 저장 공간 최소화로 비용 대폭 절감
- 중간 Iceberg 제거로 저장소 효율성 향상
- 제로 임팩트 마이그레이션으로 다운스트림 변경 없이 이행