핵심 요약
AWS의 인터커넥트 기술 분석을 통해 GPU 간 고속 통신의 설계 사상과 MoE 최적화 차이를 설명하고, GPUDirect RDMA/Async, NVSHMEM, EFA, DeepEP, PPLX-kernels의 비교를 제시합니다.
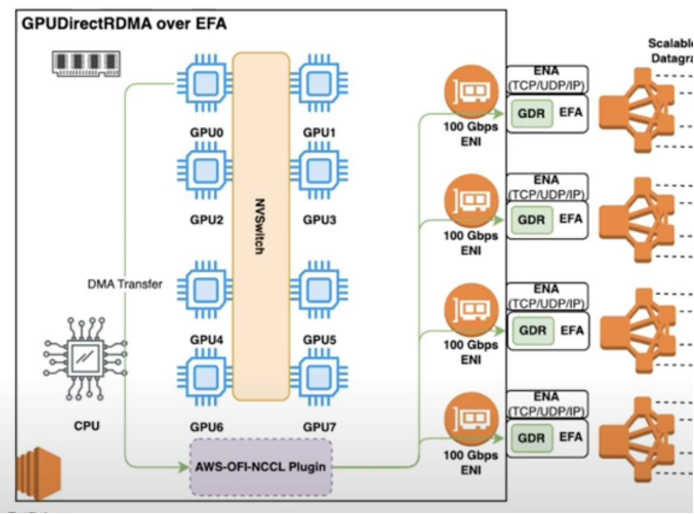
구현 방법
- GPUDirect RDMA+EFA 조합으로 데이터 경로의 CPU 개입 제거
- GPUDirect Async로 제어 경로의 지연 감소(단, AWS EFA는 IBGDA 직접 지원 아님)
- MoE의 Expert Parallelism 최적화를 위해 DeepEP와 PPLX-kernels의 아키텍처 차이 비교
주요 결과
- DeepEP V1: 소형 메시지에서 최대 9.5배 처리량 증가
- EP16(2노드)에서 PPLX-kernels가 459μs의 dispatch+combine 기록
- GDRCopy로 CPU-GPU 동기화가 1μs 미만으로 감소


