핵심 요약
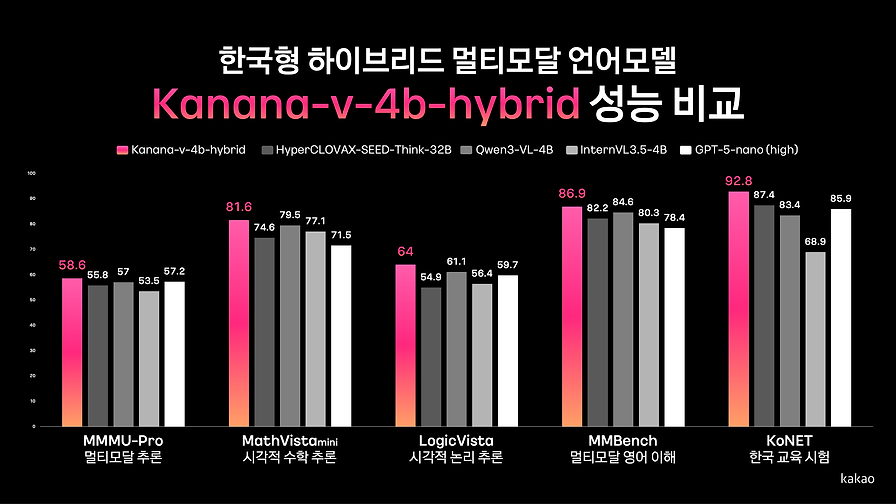
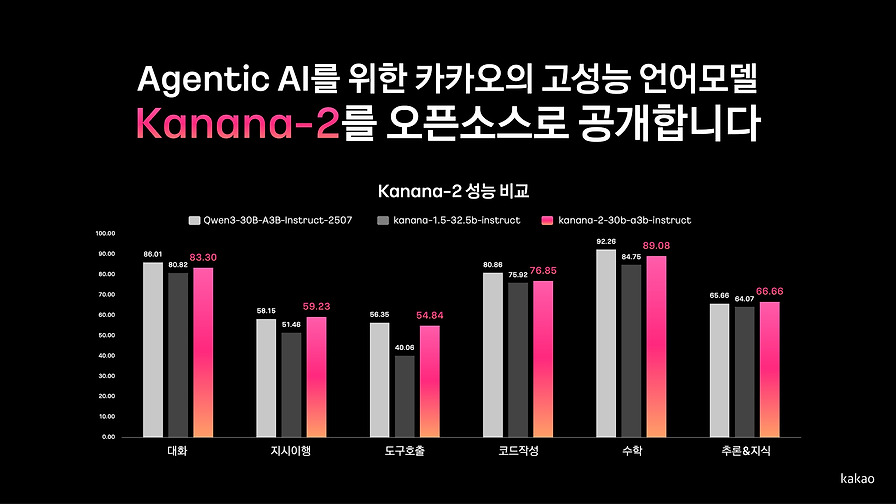
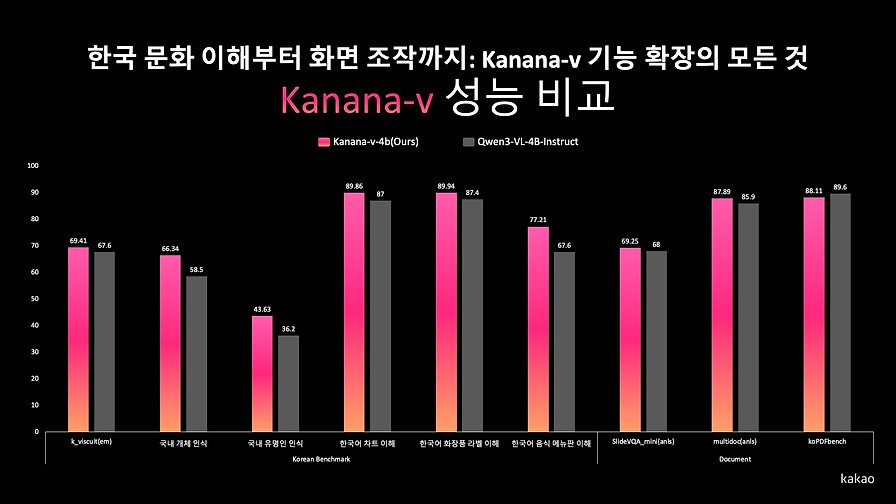
카카오가 Kanana-V 기능 확장을 통해 텍스트, 이미지, 음성을 아우르는 멀티모달 언어모델의 구현 방향을 제시합니다.
구현 방법
- 멀티모달 언어모델 아키텍처의 고도화 및 모달리티 간 상호 작용 설계
- 텍스트, 이미지, 음성 데이터를 함께 처리하는 인퍼런스 파이프라인 구축
- Vision Language Model(VLM) 기반의 텍스트-이미지 연합 해석 및 응답 생성
주요 결과
- 서비스 환경에서의 적용 가능성 확인 및 확장 포인트 제시
- 멀티모달 처리 흐름의 일관성 및 재현성 향상 가능성
- UI/UX 및 한국 문화 이해 영역으로의 적용 확장 탐색