핵심 요약
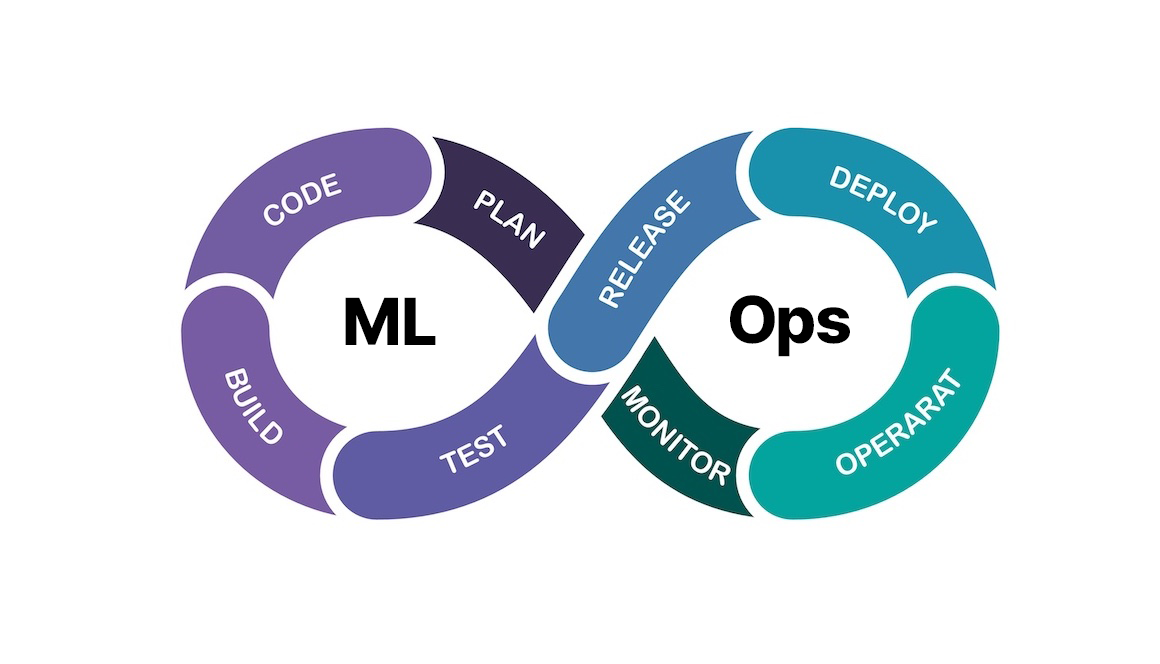
KREAM은 Kubeflow를 활용한 추천 시스템을 구축하고, Kafka·Airflow·HBase로 데이터 파이프라인을 구성해 MF 기반 모델을 학습·서빙하는 전체 MLOps 흐름을 구현했다.
구현 방법
- 데이터 파이프라인: 이벤트 → Kafka → 멀티 컨슈머 저장(Amplitude, HBase, Braze) 및 10분 간격 전처리
- 모델/서빙: Matrix Factorization(MF) 기반 학습, Kubeflow Pipelines로 파이프라인 구성, FastAPI로 추론 API 배포
- 저장/배포: PVC로 데이터 공유, Docker 이미지 기반 학습, Kubernetes에 배포
- 서빙: Kubeflow KServe를 통한 InferenceService 배포
- 튜닝/성과: Katib으로 하이퍼파라미터 자동 튜닝, 실시간 → 오프라인 추론 전환으로 응답 시간 10배 단축
주요 결과
- 응답 시간 약 10배 단축, 시스템 부하 감소
- 평가 지표로 NDCG, MAP를 활용한 성능 평가 및 재현성 확보