핵심 요약
코인원이 Prometheus와 Grafana를 활용해 쿠버네스 기반 서비스의 리소스 모니터링 체계를 실무에서 구축하고, 장애 징후 탐지와 신속한 대응 체계를 확립했습니다.
주요 경험
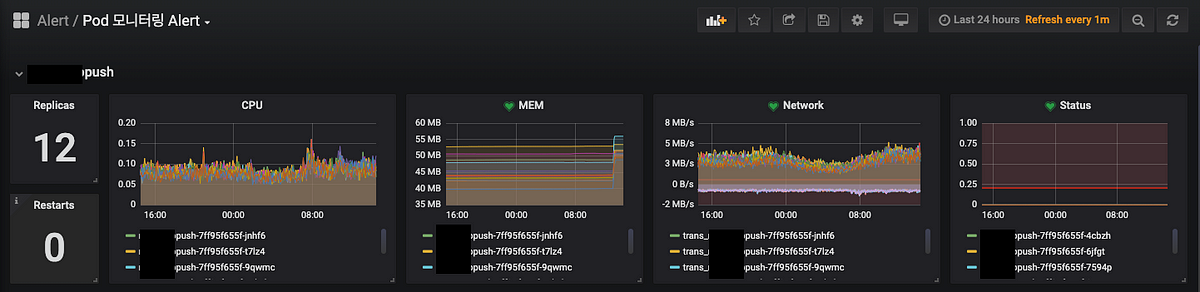
- CPU/메모리/네트워크, Pod 수/상태, Node 메모리 및 Disk 사용, Uptime 등 핵심 지표를 한 눈에 확인 가능하도록 대시보드 구성
- PromQL과 kube_deployment_metadata_generation으로 Grafana 변수 관리와 대시보드 안정성 확보
- Memory 급등 탐지 및 Slack 알림 도입으로 빠른 대응 및 이력 추적 가능
얻은 인사이트
- 핵심 지표 선별의 중요성과 현장 요구와의 정합성 강화
- Alert 전용 대시보드 도입이 알람 신뢰성과 가시성 개선
- Grafana+Prometheus 기반 모니터링이 장애 대응 시간과 운영 안정성에 기여